In this section we’ll look at some traditional tools to perform database backups and restores in our Kubernetes cluster. We’ll also look at some wrappers around those tools, allowing for scheduled backups, as well as automatically shipping backups to an S3-compatible storage, such as our MinIO service.
Note: all code samples from this section are available on GitHub.
mysqldump
We can’t talk about MySQL or MariaDB backups without the industry standard mysqldump utility and it’s MariaDB-flavored mariadb-dump (they’re the exact same executable on MariaDB containers).
In previous sections we’ve already used the mysql binary to run queries in our MariaDB containers. Using mysqldump is not that different, however, large database dumps can be somewhat resource intensive, so it’s always recommended to perform them on a replica server if possible.
$ kubectl get mariadbs
NAME READY STATUS PRIMARY POD AGE
wordpress-mariadb True Running wordpress-mariadb-0 78m
In our configuration, wordpress-mariadb-0 is the primary pod, so our -1 and -2 servers are replicas. Here’s a single-transaction dump from our first replica:
$ kubectl exec wordpress-mariadb-1 -- \
mysqldump -uroot -pverysecret wordpress \
--single-transaction
We can pipe this into a compressed file on our local system:
$ kubectl exec wordpress-mariadb-1 -- \
mysqldump -uroot -pverysecret wordpress \
--single-transaction | gzip -c9 \
> $(date +"%Y-%m%d-%H%M%S").sql.gz
This is useful if you need to quickly create a database dump for your local development environment or some local analysis. It’s also quite useful if you’re migrating an existing database from elsewhere into Kubernetes, and may have some existing backup scripts, which can be adapted to fit this format.
Restore a database
Similar to mysqldump we can use mysql to restore the data into our production cluster. Note that we do need to do this on the primary server as it’s the only one accepting writes:
$ gzcat 2024-0724-103130.sql.gz | kubectl exec -i \
wordpress-mariadb-0 -- mysql -uroot -pverysecret \
wordpress
After a database import it’s usually advised to flush the WordPress object cache (if it’s persistent). We’ll cover object caching and running CLI commands in a Kubernetes-based WordPress installation in a future section.
In addition to being able to run these traditional tools, the MariaDB operator provides several abstractions for convenience.
Operator Backups
The MariaDB Operator provides a coupe of custom resources to help with backups and restores. These abstractions are called Backup and Restore and use underlying Kubernetes Jobs and CronJob resources.
Unlike the mysqldump examples above, which produce the SQL dump files on the computer running kubectl, the operator Backup and Restore jobs run within the Kubernetes cluster context. This requires them to explicitly define the destination for their backups. These can be persistent volumes within the Kubernetes cluster, or S3-compatible storage services (external or internal).
Let’s create an example Backup resource:
apiVersion: k8s.mariadb.com/v1alpha1
kind: Backup
metadata:
name: wordpress-backup
spec:
mariaDbRef:
name: wordpress-mariadb
storage:
persistentVolumeClaim:
storageClassName: openebs-hostpath
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnce
This creates a one-time backup job that claims a 100Mi persistent volume and performs the backup. As with other MariaDB related resources, we tell it which cluster to backup using the mariaDbRef attribute.
Let’s call this manifest mariadb.backup.pvc.yml and add it to our Kubernetes cluster:
$ kubectl apply -f mariadb.backup.pvc.yml
backup.k8s.mariadb.com/wordpress-backup created
$ kubectl get jobs
NAME STATUS COMPLETIONS DURATION AGE
wordpress-backup Complete 1/1 8s 72s
$ kubectl get backups
NAME COMPLETE STATUS MARIADB AGE
wordpress-backup True Success wordpress-mariadb 14s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
wordpress-backup-mb96d 0/1 Completed 0 20s
We’ve omitted some output from the pods list, but as you can see the backup resource creates a Kubernetes Job resource, which launches a Pod that claims a persistent volume and ultimately runs mysqldump.
CronJobs
Jobs in Kubernetes are single-use. We can’t re-run them on demand, so for every such manual backup, we’ll need to create a new job. We can, however use CronJobs in Kubernetes, which are a great fit for database backups and other maintenance tasks.
The Backup resource of the MariaDB operator supports a Cron schedule, as well as a maxRetention property. Let’s delete our existing backup:
$ kubectl delete -f mariadb.backup.pvc.yml
backup.k8s.mariadb.com "wordpress-backup" deleted
Now let’s update our manifest to include a schedule and our max retention. For testing purposes we’re going to create a backup every minute, with a 10 minute retention:
apiVersion: k8s.mariadb.com/v1alpha1
kind: Backup
metadata:
name: wordpress-backup
spec:
mariaDbRef:
name: wordpress-mariadb
schedule:
cron: "*/1 * * * *"
maxRetention: 10m
storage:
persistentVolumeClaim:
storageClassName: openebs-hostpath
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnce
Let’s re-create this resource in the Kubernetes cluster and look around:
$ kubectl apply -f mariadb.backup.pvc.yml
backup.k8s.mariadb.com/wordpress-backup created
$ kubectl get cronjobs
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
wordpress-backup */1 * * * * <none> False 0 34s 3m26s
$ kubectl get jobs
NAME STATUS COMPLETIONS DURATION AGE
wordpress-backup-28697081 Complete 1/1 5s 3m2s
wordpress-backup-28697082 Complete 1/1 5s 2m2s
wordpress-backup-28697083 Complete 1/1 4s 62s
wordpress-backup-28697084 Running 0/1 2s 2s
As you can see, this CronJob is now creating new Jobs in our Kubernetes cluster every minute, which are creating Pods, running mysqldump with our persistent volume attached.
Browsing PVCs
Often times when working with persistent volumes in Kubernetes, you might want to browse that volume, to perhaps download a specific file, or even update a configuration file in place when debugging an application.
We can do this in Kubernetes by creating a new Pod that mounts the persistent volume and runs a busybox container, allowing us to shell in and explore. Let’s create our Pod manifest:
apiVersion: v1
kind: Pod
metadata:
name: pvc-browser
spec:
containers:
- image: busybox
name: pvc-browser
command: ['sleep', 'infinity']
volumeMounts:
- mountPath: /pvc
name: pvc-mount
volumes:
- name: pvc-mount
persistentVolumeClaim:
claimName: wordpress-backup
This manifest runs a pod in our cluster that claims the same wordpress-backup PVC and mounts it into the /pvc directory in our busybox container that infinitely sleeps. Let’s call this manifest pvc-browser.yml and add it to our Kubernetes cluster:
$ kubectl apply -f pvc-browser.yml
pod/pvc-browser created
$ kubectl exec -it pvc-browser -- sh
# ls -lh /pvc
total 27M
-rwxrwxrwx 1 999 999 31 Jul 24 12:58 0-backup-target.txt
-rw-rw-r-- 1 999 999 2.7M Jul 24 12:49 backup.2024-07-24T12:49:00Z.sql
-rw-rw-r-- 1 999 999 2.7M Jul 24 12:50 backup.2024-07-24T12:50:00Z.sql
-rw-rw-r-- 1 999 999 2.7M Jul 24 12:51 backup.2024-07-24T12:51:00Z.sql
As mentioned, this is incredibly useful not just for backups, but for looking around volumes in general when working with Kubernetes. You can use kubectl cp to copy these files to your local computer if needed too.
Do note, however, that some storage classes will not allow multiple pods to claim the same volume, even if they’re on the same node. This means that your backups may be failing while the browser pod is running.
After having the CronJob running for a while, you’ll notice that the 10 minute retention policy works as expected, deleting backups that are older than 10 minutes.
Let’s delete the browser pod, backup configuration and backup volume before looking at shipping backups to S3.
$ kubectl delete -f pvc-browser.yml -f mariadb.backup.pvc.yml
pod "pvc-browser" deleted
backup.k8s.mariadb.com "wordpress-backup" deleted
$ kubectl delete pvc wordpress-backup
persistentvolumeclaim "wordpress-backup" deleted
Backups to S3
We’ve configured a MinIO instance in a previous section for saving WordPress media uploads to an S3-compatible storage. Let’s use the same MinIO instance to hold our MariaDB database backups.
First, let’s use the MinIO console to create a new bucket called mariadb, and an access key/secret, and add those to our existing mariadb.secrets.yml:
apiVersion: v1
kind: Secret
metadata:
name: mariadb-secrets
labels:
k8s.mariadb.com/watch:
stringData:
MARIADB_PASSWORD: secret
MARIADB_ROOT_PASSWORD: verysecret
MINIO_ACCESS_KEY: O112zy6WaWTjZ4BQpqgd
MINIO_SECRET_KEY: Bpqe8KqWl6bLsLNmizj1ebwClmNCkOsKDioKHTMs
Next we’ll create a new manifest called mariadb.backup.s3.yml with our S3 storage configuration:
apiVersion: k8s.mariadb.com/v1alpha1
kind: Backup
metadata:
name: wordpress-backup-s3
spec:
mariaDbRef:
name: wordpress-mariadb
schedule:
cron: "*/1 * * * *"
maxRetention: 10m
storage:
s3:
bucket: mariadb
endpoint: minio:9000
accessKeyIdSecretKeyRef:
name: mariadb-secrets
key: MINIO_ACCESS_KEY
secretAccessKeySecretKeyRef:
name: mariadb-secrets
key: MINIO_SECRET_KEY
Note that the storage.s3.endpoint contains our minio service name and port, which is a Kubernetes ClusterIP service defined in a previous section when configuring MinIO.
We set the storage.s3.bucket name to the mariadb bucket we created moments ago, and link to the access and secret keys from the mariadb-secrets resource.
Let’s apply both manifests to our Kubernetes cluster:
$ kubectl apply \
-f mariadb.secrets.yml \
-f mariadb.backup.s3.yml
secret/mariadb-secrets configured
backup.k8s.mariadb.com/wordpress-backup-s3 created
Wait a few minutes and see our backup jobs (hopefully) succeeding:
$ kubectl get jobs
NAME STATUS COMPLETIONS DURATION AGE
wordpress-backup-s3-28697152 Complete 1/1 4s 2m13s
wordpress-backup-s3-28697153 Complete 1/1 4s 73s
wordpress-backup-s3-28697154 Complete 1/1 5s 13s
This can also be observed via the MinIO web console:
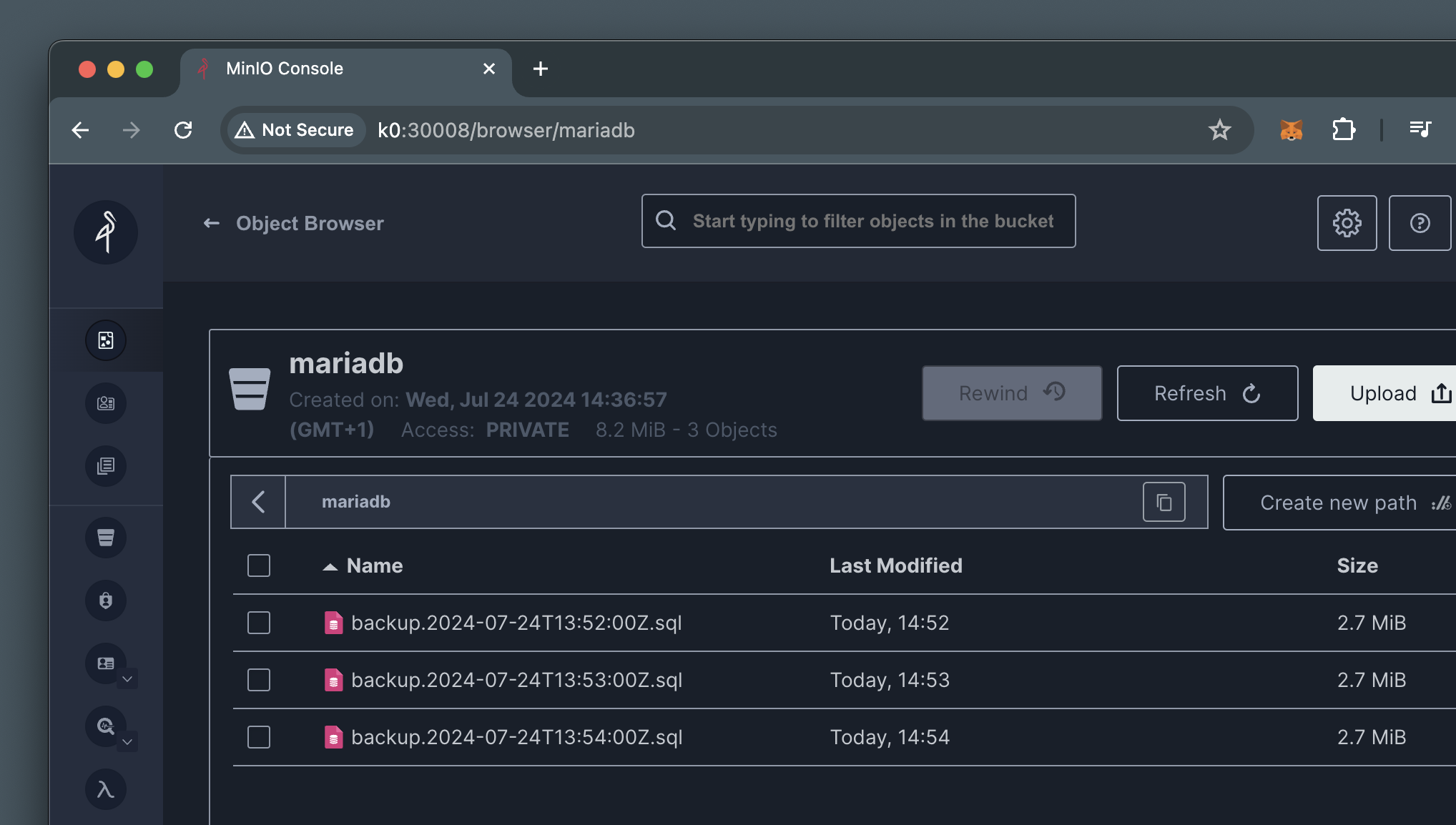
The backups jobs will also take care of deleting older backups which no longer fit the retention policy, just like the PVC-based backups.
Restoring Backups
The final piece of the puzzle is the ability to restore the backups created with the MariaDB operator. This can be achieved using the Restore custom resource provided by the operator:
apiVersion: k8s.mariadb.com/v1alpha1
kind: Restore
metadata:
name: restore
spec:
mariaDbRef:
name: wordpress-mariadb
backupRef:
name: wordpress-backup
A backup object is linked to a MariaDB cluster via the mariaDbRef property, and a backup object via the backupRef reference. Creating this restore object in our Kubernetes cluster will immediately launch a restoration job, that will import the latest MariaDB backup that’s available in the linked backup resource.
$ kubectl apply -f mariadb.restore.yml
restore.k8s.mariadb.com/restore created
$ kubectl get restores
NAME COMPLETE STATUS MARIADB AGE
restore True Success wordpress-mariadb 8s
Of course getting the latest backup is not always the one we need. That’s where the targetRecoveryTime attribute comes in, which allows us to specify a specific timestamp, and the MariaDB operator will look for an available backup that’s closest to that recovery time.
Let’s create a restore resource with a target recovery time that’s the beginning of the Unix epoch:
apiVersion: k8s.mariadb.com/v1alpha1
kind: Restore
metadata:
name: restore
spec:
mariaDbRef:
name: wordpress-mariadb
backupRef:
name: wordpress-backup
targetRecoveryTime: 1970-01-01T00:00:00Z
Deleting and re-creating this resource should return our MariaDB cluster to a state that’s the earliest available backup:
$ kubectl delete -f mariadb.restore.yml
restore.k8s.mariadb.com "restore" deleted
$ kubectl apply -f mariadb.restore.yml
restore.k8s.mariadb.com/restore created
Of course as demonstrated earlier, you could always download the specific backup file, modify as needed, and import explicitly to the primary database pod using the mysql command line utility.
What’s next?
There are a few other options for backups and restores via the MariaDB operator which may be useful, especially if you’re running a database cluster that’s used across multiple applications. We encourage you to explore these, as well as the various options you can pass to mysql and mysqldump to balance between speed, compatibility, etc.
In this section we looked at using traditional mysqldump and mysql utilities to create and restore MySQL and MariaDB backups. We also looked at the custom resources provided by the MariaDB operator, to create, restore and schedule backups stored in a persistent volume or an S3 compatible storage.
In the next section we’ll look at some disaster recovery options for when things go really bad.